Is the AI Subsidy Era Ending? And Why That Might Be a Good Thing
![]() written by Stefan Christoph
written by Stefan Christoph
I was listening to a recent episode of The AI Daily Brief — “The AI Subsidy Era Is Over” — and my thoughts started spinning. Not because the argument was new, but because it connected dots I’d been seeing separately for months: pricing changes in the tools I use daily, conversations with customers about AI cost models, and a growing sense that the “unlimited for $20” era was living on borrowed time.
The host laid out the case clearly: even $200/month AI plans don’t cover the actual inference cost for power users. The gap has been filled by venture capital. And with agentic usage exploding token consumption, that gap is becoming a chasm.
But here’s the thing, none of this should be surprising.
This Has Happened Before
Every significant technology goes through a subsidy phase. It’s not a bug, it’s a feature of how technological revolutions work.
Carlota Perez, the Venezuelan economist who literally wrote the book on this pattern (Technological Revolutions and Financial Capital, 2002), describes a recurring cycle that has played out five times since the Industrial Revolution. Each technological surge splits into two periods: an installation phase, where financial capital floods in, infrastructure gets built, and prices are artificially low to drive adoption, followed by a deployment phase, where the technology matures, pricing reflects real costs, and the actual value creation begins.
The transition between these phases is messy. Perez calls it the “turning point.” It involves a recomposition of the relationship between financial and production capital. In plain language: the venture money that funded the land grab gives way to sustainable business models. Prices go up. Weaker players consolidate or disappear. And the technology becomes genuinely useful, not because it got better, but because the economics got honest.
If this sounds abstract, look at the concrete examples from the past fifteen years.
The Millennial Lifestyle Subsidy (2012–2019)
The term was coined to describe a specific phenomenon: Silicon Valley venture capital was subsidizing the daily lives of urban consumers through artificially cheap services. The pattern was everywhere:
Ride-sharing: Uber launched in 2012 with prices deliberately set below the cost of providing the ride. By 2019, Uber had lost over $8 billion cumulatively. Lyft reported roughly $1 billion in losses in a single quarter. The rides were cheap because investors, not riders, were paying the difference. When the subsidies ended, prices rose 40–60% in many markets. Riders who’d built their lives around $8 rides across town suddenly faced $15–20 fares. The service was the same. The price was just real now.
Food delivery: DoorDash, Uber Eats, and their competitors operated at massive losses to build market share. Free delivery, generous promotions, and below-cost pricing were the norm. When profitability became the goal, delivery fees appeared, service fees increased, and the “convenience premium” became visible. The value was always there, but so was the cost.
Streaming media: Netflix, Disney+, and their competitors spent the 2010s and early 2020s in a content arms race funded by subscriber growth projections and cheap capital. Netflix alone spent $17 billion on content in 2022. Subscription prices were kept artificially low. Netflix launched at $7.99/month in 2010 and barely moved for years. The result was extraordinary adoption: hundreds of millions of subscribers worldwide got used to unlimited premium content for the price of two coffees. Then the economics caught up. Between 2022 and 2025, every major streaming platform raised prices, introduced ad-supported tiers, cracked down on password sharing, and started licensing content to competitors. Netflix’s standard plan went from $9.99 to $17.99. The content didn’t get worse. The price just got real. And the platforms that survived were the ones that built sustainable content economics, not the ones that spent the most.
The Gartner Hype Cycle Parallel
Gartner’s Hype Cycle offers another lens on the same phenomenon. The five phases. Technology Trigger, Peak of Inflated Expectations, Trough of Disillusionment, Slope of Enlightenment, Plateau of Productivity, map surprisingly well to pricing cycles:
| Hype Cycle Phase | Pricing Equivalent | AI Coding Tools |
|---|---|---|
| Technology Trigger | Free tiers, open betas | 2022: Copilot preview, free access |
| Peak of Inflated Expectations | “Unlimited” plans, VC-subsidized pricing | 2023–2024: $10–20/mo “unlimited” everything |
| Trough of Disillusionment | Price increases, usage limits appear, users feel betrayed | Late 2025: Credits, quotas, premium tiers emerge |
| Slope of Enlightenment | Usage-aware pricing, cost optimization tools | 2026: Credit-based models, token transparency |
| Plateau of Productivity | Mature, sustainable pricing that reflects real value | Coming: The pricing model that survives |
The Perez Framework Applied to AI
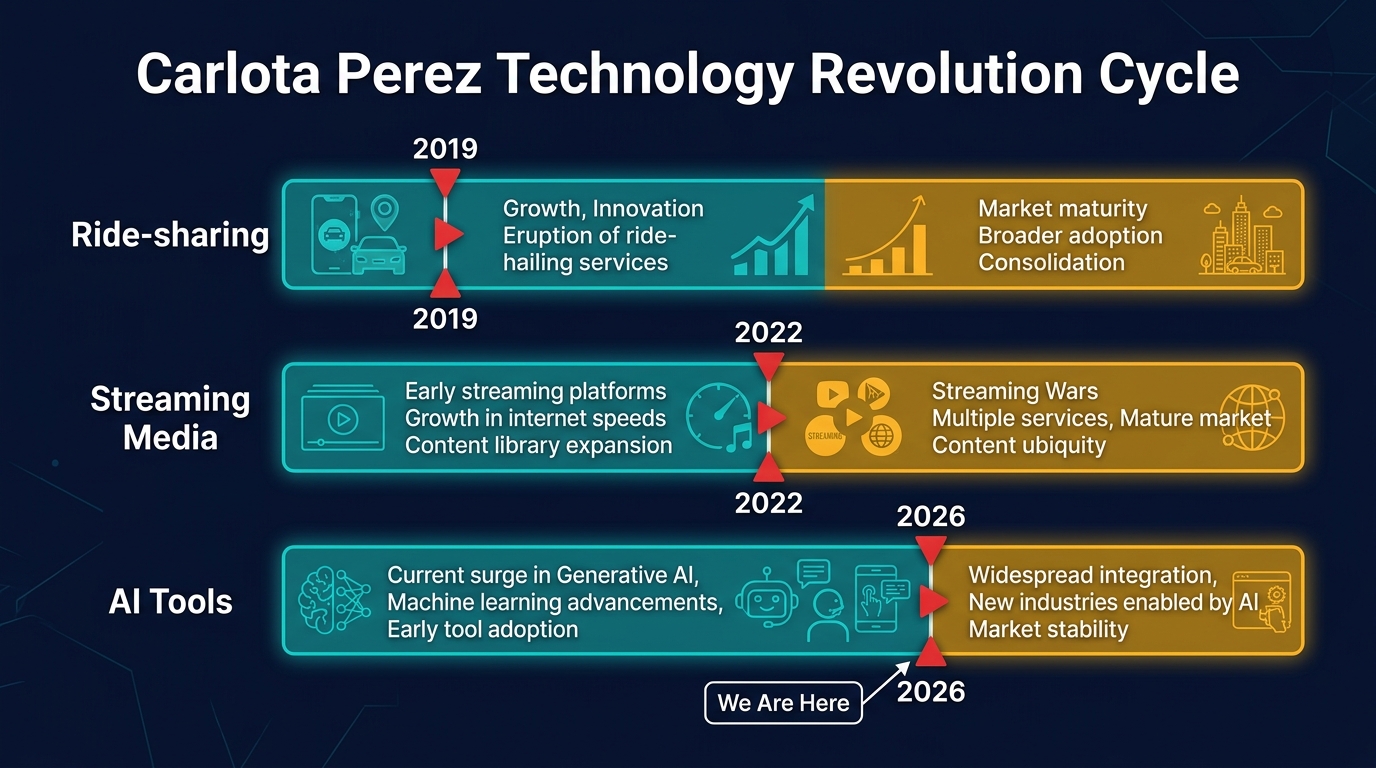
Each technology goes through the same installation-to-deployment pattern, but at different times. AI tools are at the turning point now.
Mapping Perez’s framework specifically to AI:
Installation phase (2022–2025): Financial capital floods in. Billions in venture funding. Every major tech company launches an AI coding tool. Pricing is set to maximize adoption, not cover costs. “Unlimited” plans proliferate. Infrastructure gets built (data centers, custom chips, model training). The technology reaches millions of users who wouldn’t have tried it at real prices.
Turning point (2025–2026): The subsidies become unsustainable. Agentic usage patterns break the flat-fee model. Providers introduce usage-aware pricing. Weaker players consolidate. Users who built workflows around artificially cheap AI face price adjustments.
Deployment phase (2026+): Pricing reflects real costs. Optimization becomes a discipline. The technology delivers genuine value, not because it improved, but because the economics are honest and sustainable. The builders who planned for real costs thrive. The ones who assumed cheap was permanent struggle.
We’re in the turning point right now. The same place ride-sharing was in 2019, and streaming was around 2022. And that’s exactly where you want to be paying attention.
What Actually Happened in AI
With that historical context, let’s look at the specific mechanics of how the AI subsidy era played out, and why agentic coding was the trigger that broke it.
The AI subsidy era followed a familiar playbook. In 2022–2023, AI coding assistants launched at $10–20/month with generous or “unlimited” usage. The economics didn’t work, reports suggested some providers were losing $20–80 per user per month, but the goal was adoption, not profit.
That model held as long as usage was predictable: autocomplete suggestions, occasional chat queries, maybe a code explanation. Token consumption per session was bounded.
Then agentic coding arrived.
When developers started running multi-step, autonomous coding sessions, agents that read entire codebases, plan changes across dozens of files, execute tests, and iterate, token consumption exploded. A single power user could burn through what previously served dozens of casual users. The flat-fee model broke not because the price was wrong, but because the usage pattern fundamentally changed.
The response has been swift. Across the industry, we’re seeing a convergence toward usage-aware pricing: credits, tokens, quotas, premium request pools. The “unlimited” era lasted roughly two years. In hindsight, that’s about right for a technology subsidy cycle.
Why This Is Good News
Here’s where my perspective might differ from the panic narrative. The end of subsidized pricing is healthy. Three reasons.
First, it encourages optimization. When AI is “free” (or feels free), there’s no incentive to use it efficiently. Why bother routing a simple classification task to a small model when the big model is included in your flat fee? Why cache prompts when tokens are unlimited? Realistic pricing creates a natural pressure to build better, leaner systems. At Amazon, we call this Frugality, one of our Leadership Principles. It’s not about spending less or accepting austerity. It’s about accomplishing more with less, getting more value from every resource you use. The builders who internalize this will have a structural cost advantage over those who wait for subsidies to return.
Second, it makes the market honest. Subsidized pricing distorts decision-making. Teams choose tools based on sticker price rather than total cost of ownership. When every tool costs $20/month, the differentiator becomes marketing, not engineering. Usage-aware pricing reveals which tools are actually efficient and which were hiding behind venture capital.
Third, agentic AI is worth the real price. The value that AI coding tools deliver, when used well, is substantial. I’ve written about the productivity patterns that actually work: staying on the loop rather than in it [1], investing patience in agent setup [2], redesigning workflows around what agents are good at [3]. The builders who’ve internalized these patterns aren’t worried about paying more. They’re getting more.
Six Pricing Models — And Why Most Won’t Survive
The market is experimenting with six approaches. Not all will survive.
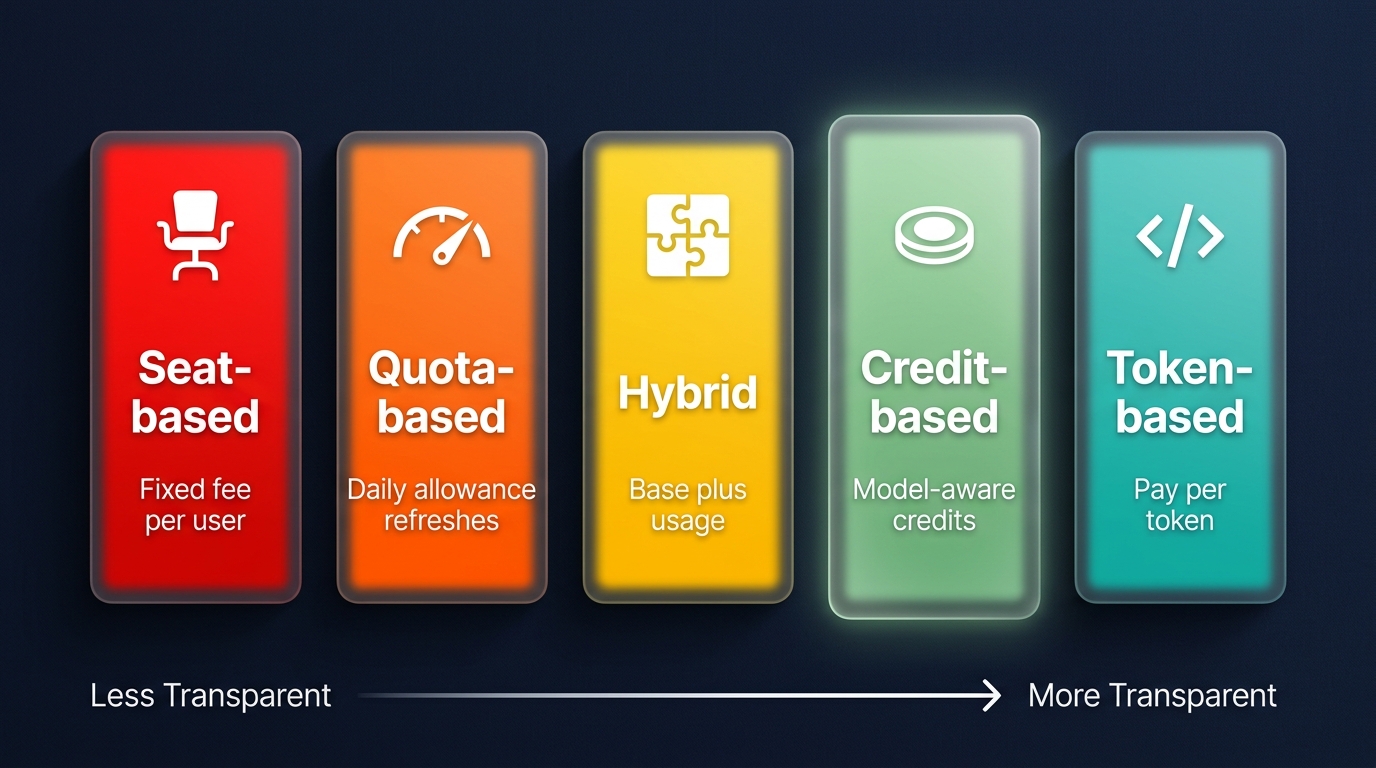
The transparency spectrum: from opaque flat fees to fully transparent token pricing. Credit-based sits at the sweet spot.
Seat-based (flat fee) is the legacy model. Fixed monthly cost regardless of usage. Simple to understand, impossible to sustain for variable-cost AI workloads. Every provider that started here is moving away from it.
Quota-based gives you a daily or weekly usage allowance that refreshes automatically. Better than flat fee, but opaque, “what counts as one unit?” is rarely clear. Hit your limit and you’re blocked until tomorrow.
Hybrid combines a base subscription with a usage component. Increasingly common, but complex. Two billing dimensions to track, and the interaction between them is often confusing.
Token-based (pay-per-use) is the most transparent. You pay exactly for what you consume, per model, per token. This is how Amazon Bedrock works, and it’s the model that gives builders the most control. But it requires engineering effort to optimize and can be unpredictable for budgeting.
Credit-based is where I see the best balance. A monthly credit allocation, with credits consumed at different rates depending on model and task complexity. Overage is opt-in and transparent. Kiro’s model is a good example: fractional credits (charged to 0.01 precision), model-aware consumption (cheaper models cost fewer credits), and a clear overage rate ($0.04/credit). You see what you use, you can optimize by choosing the right model for the task, and you’re never surprised by the bill.
The credit model works because it shares the cost risk fairly between provider and user. The provider commits to a base price. The user commits to being thoughtful about consumption. Neither side is subsidizing the other.
Outcome-based is the emerging sixth model, and potentially the most interesting. Instead of charging for compute (tokens, credits, seats), you charge for results: per document processed, per ticket resolved, per report generated. The customer pays for value received, not infrastructure consumed.
SAP’s CTO Philipp Herzig discussed this shift on the No Priors podcast [12]: SAP is exploring outcome-based pricing for AI features, but customers aren’t necessarily ready for it. The transition requires a joint journey between service provider and customer, both sides need to agree on what constitutes an “outcome” and how to measure it. It’s a maturity curve, not a switch you flip.
My take: outcome-based pricing is the right long-term direction, but it only works when the underlying cost is factored in. If you charge $0.50 per document summarized but your inference cost is $0.80, you’re back to subsidizing. The sustainable version is outcome-based pricing with cost-aware architecture underneath, you optimize your inference costs (model routing, caching, batching) until the margin works, then price the outcome. The customer gets simplicity and value alignment. You get sustainability.
A Note on Token Cost Deflation
A fair counterargument: token prices are falling roughly 10x every 18 months. Won’t “unlimited” become sustainable again as inference gets cheaper?
Probably not, because agentic usage is growing faster than prices are falling. A single coding agent session today consumes 10–100x more tokens than a chat session in 2023. The cost curve and the usage curve are racing each other, and usage is winning. Cheaper tokens don’t help if every user is consuming orders of magnitude more of them.
What Builders Should Do
If you’re building AI-powered products for customers, the subsidy era ending changes your calculus in three ways.
1. Architect for Cost Awareness
The single most impactful pattern is model routing: don’t send every request to your most expensive model. A lightweight classifier can assess query complexity and route accordingly. Simple tasks go to a small, fast model. Complex reasoning goes to a frontier model. The cost difference is 6–10x.
On Bedrock, this translates to concrete savings. Haiku 4.5 costs $0.80 per million input tokens. Sonnet 4.6 costs $3.00. Opus 4.7 costs $5.00. If 70% of your queries can be handled by Haiku, you’ve just cut your inference bill by more than half, without any quality loss on those queries.
Prompt caching is the second lever. If your application sends the same system prompt or document context repeatedly, caching avoids recomputing it on every call. On Bedrock, cached token reads cost 90% less than fresh input. A well-designed caching strategy routinely cuts input costs by 85–90%.
2. Price Your Product Honestly
If you’re charging customers for an AI-powered feature, your pricing model needs to reflect your cost structure. Three principles:
Don’t promise unlimited. It’s a subsidy you’ll have to walk back. When you do, customers feel betrayed. Be upfront about limits from day one.
Make costs visible. A usage dashboard isn’t a nice-to-have, it’s a trust mechanism. When customers can see what drives their bill, they make better decisions and complain less.
Align incentives. If your customer uses a cheaper model for a simple task, they should pay less. This isn’t just fair, it’s efficient. Credit-based or token-based pricing naturally creates this alignment. Flat fees don’t.
3. Build Cost Observability From Day One
Only 15% of GenAI deployments currently have LLM observability, according to Gartner [7]. The rest are flying blind on token costs. If you can’t see your per-customer, per-feature, per-model costs in real time, you can’t price fairly, you can’t optimize, and you can’t explain your bill to a customer who asks.
Bedrock’s granular cost attribution, which now tracks costs per IAM principal, is a starting point. But you need application-level observability too: which features consume the most tokens, which customers are outliers, which prompts are inefficient.
The Trust Equation

The three components of pricing trust.
Ultimately, pricing is a trust problem. Your customers are making a bet: they’re paying you money in exchange for AI capabilities, and they’re trusting that the price reflects the value.
That trust has three components:
- Transparency: Can they see what drives the cost?
- Predictability: Can they estimate next month’s bill?
- Fairness: Does a light user pay less than a heavy user?
The subsidy era optimized for predictability (flat fee, easy to budget) at the expense of transparency and fairness. The post-subsidy era needs to optimize for all three.
Credit-based pricing, backed by token-level infrastructure like Bedrock, is the model that gets closest. It’s transparent (you see credit consumption), predictable (monthly allocation with known overage rates), and fair (model-aware pricing means efficient usage costs less).
The Builders Who Win
The end of the AI subsidy era isn’t a setback. It’s a maturation. The technologies that changed the world, cloud, mobile, SaaS, all went through this transition. The builders who thrived weren’t the ones who found the cheapest option. They were the ones who understood the real costs, built efficient systems, and earned their customers’ trust with honest pricing.
The same will be true for AI. The subsidy era gave us adoption. The post-subsidy era will give us sustainability. And sustainability is what lets you build something that lasts.
If You’re Running This on AWS
Amazon Bedrock provides the infrastructure for cost-aware AI applications:
- Model routing: Use Bedrock’s Intelligent Prompt Routing to automatically select the most cost-effective model per query, or build your own router with a Haiku classifier
- Prompt caching: Enable on supported models, cache reads at $0.50/1M tokens vs. $3–5/1M for fresh input [4]
- Batch inference: 50% cost reduction for non-real-time workloads (nightly reports, bulk processing)
- Model Distillation: Train a smaller, cheaper model on Opus outputs for well-defined tasks, up to 75% cost reduction
- Cost attribution: Per-IAM-principal cost tracking lets you see exactly what each customer, team, or feature costs to serve [5]
- Provisioned throughput: For steady-state workloads, reserved capacity provides predictable pricing
The Well-Architected Generative AI Lens [6] covers these patterns in detail, including prompt caching implementation and cost optimization best practices.
Sources
[1] Stefan Christoph, “On the Loop: Why AI Code Quality Depends on You, Not the Model” — schristoph.online/blog/on-the-loop-code-quality/
[2] Stefan Christoph, “AI Agents Require Patience” — schristoph.online/blog/ai-agents-require-patience/
[3] Stefan Christoph, “The Bottleneck Moved: What 10 Studies Say About AI Developer Productivity” — schristoph.online/blog/bottleneck-moved-productivity/
[4] AWS, “Amazon Bedrock Cost Optimization” — aws.amazon.com/bedrock/cost-optimization/
[5] AWS, “Introducing Granular Cost Attribution for Amazon Bedrock” — aws.amazon.com/blogs/machine-learning/
[6] AWS, “Well-Architected Generative AI Lens: Prompt Caching” — docs.aws.amazon.com/wellarchitected/latest/generative-ai-lens/gencost03-bp03.html
[7] Gartner, “Explainable AI Will Drive LLM Observability Investments to 50% of GenAI Deployments by 2028, Up from 15% Today” (March 2026) — gartner.com/en/newsroom/press-releases/2026-03-30
[8] Carlota Perez, Technological Revolutions and Financial Capital: The Dynamics of Bubbles and Golden Ages (2002)
[9] Gartner, “Understanding Gartner’s Hype Cycles” — gartner.com/en/articles/understanding-gartner-hype-cycles
[10] The Atlantic, “The Millennial Lifestyle Is About to Get More Expensive” (2019)
[11] BusinessWorld, “Subsidised Intelligence Will Soon Face The Discipline Of Real Pricing” (2026)
[12] No Priors Podcast, “SAP: Bringing the ‘Operating System’ of a Company into the AI Era with CTO Philipp Herzig” (2026)
About the Author
Stefan Christoph is a Principal Solutions Architect at AWS, focused on agentic AI, media & entertainment, and helping builders move from demo to production. He writes about AI architecture, developer productivity, and the future of software.
This is a personal blog. Opinions expressed here are my own and do not represent the views or positions of my employer.