IT System Maintenance in the age of AI
IT System Maintenance in the age of AI
Introduction - The Maintenance Trap in IT
You don’t need to be in the IT industry for long to have witnessed this firsthand. Even non-IT users do. Those systems that haven’t been maintained for ages. From a user perspective, you “just” see a maybe aged user interface, non-evolving features, and old bugs or quirks become accepted by, possibly generations of, users. From a user perspective, you should have an eye on this. Often, this not only means that the system becomes cumbersome to use, but it also means that there are possibly no security updates being made. We will see just in a bit that it might even not be possible anymore. So think about which kind of data you want to put in there.
If you look closer into those systems, you can see that they consist of software and hardware.
The Hardware Lifecycle
Hardware is easy to grasp. We all had that phone in our pockets which got slower and slower, battery life became more and more of a problem, and maybe eventually we didn’t get any updates anymore. Maybe we were even patient enough not to upgrade, only to see it break and stop working. Server hardware is different but similar. It also has a finite lifetime in terms of how long the hardware works and how long you get spare or extension parts. This is physics. But also, typically software stops supporting very old hardware at some point in time. You don’t get an update anymore. And then, most of the larger companies and enterprises are running business-relevant services on this hardware, so they decide to require support from vendors for their hardware. They can’t afford to have a business discontinuity just because some hardware fails and can’t be repaired or replaced. Also—often more important for enterprises—there is no one external to blame. Hence we need vendor support.
What About the Software Lifecycle?
Well, software is easier to change than hardware, but this also means that unchanged software ages relatively fast. Not updating to newer versions usually means that new features and, more importantly, bug fixes and security fixes are not made available for the software. This is true on many layers.
Taking from the Shelf…
Obviously, when you buy—or quite more often license—software, the software vendor will provide those only in newer versions as they often stop maintaining older versions of software. This is in essence not pure evil but just a matter of protecting themselves from being overwhelmed by maintaining many different versions at the same time. Sometimes they force customers to upgrade for other reasons, but this would be too much of a deviation at this point in the article. So in this case, you would need to update your software frequently, but each time this requires effort. You need to deploy the new version of the software, test it to make sure that it works for your use case as expected, and most likely you need to iron out some incompatibilities. This takes time and effort—especially if you are not able to rely on automated tests which give you an accurate view of how well a new version of the software works for you.
Roll Your Own…
When you build your own software, you also have the need to maintain it. Often, this sounds even more counterintuitive to business owners than the need to update off-the-shelf software. This is specifically the case if no new features are asked for by the business. Why would we change anything? The reality is that the self-built software is based on existing software components like libraries, which have their own lifecycle and require updates to get the latest bug and security fixes. Often, we see cascading update requirements through the entire software stack. For example, a new operating system version requires an updated programming language version, which requires new libraries, and so on. Again, we need to test carefully and also, often neglected, we need the right skill sets in the team to do all of this. Knowledge often vanishes over time as team structures change, technologies get out of fashion, and are harder to acquire.
Delaying Updates and You Are—Trapped!
A common trap a lot of organizations fall into is to assess the risk of running an outdated version of software or hardware, the business value created by the update, the cost in time and labor, and the lost opportunity cost of spending the effort on something else, with the conclusion to either “just” skip intermediate updates or stop updating at all. In either case, the cost of updates increases over time, as the larger the gap is, the more difficult and time-consuming an update becomes. This is often necessary for various reasons including, for example: 1) new hardware is required to replace broken old hardware; 2) old stack is not running anymore on the old hardware; 3) due to new or accumulated security risks, an update can’t be postponed anymore.
We could continue this list, but one thing happens often regardless of what is the reason for this urgent update. Complexity tends to explode due to the many changes required, and the knowledge to execute the changes in the team collapses. If we then don’t have a good set of tests which allows us to determine if the updated system still works as expected, or don’t even have a clear view of what “good” could mean, we are doomed. Many of us have been there or observed the situation.
Any Lessons Learned?
What we could have learned from this is to make sure that we run regular updates and ensure that we have automated tests to always ensure that the system is working as expected. While we can delegate some of this to, for example, SaaS providers, we always need to make sure that the entire system can be regularly updated. Basically, we need to keep our software systems alive. They are more like plants than stones in terms of maintenance.
Reality is: we haven’t in many cases.
How Does That Change in the Age of AI?
Now back to the start. What happens with the maintenance trap in IT in the age of AI? Are we doomed? Are we healed?
Neither is what I would argue. But there are two main themes I see there.
-
First of all, it becomes easier and more affordable to update software systems.
-
Second of all, there are new kids on the block. We now build systems which contain or make use of AI systems. So we have new subsystems which we need to maintain.
Some things don’t change conceptually. We need to have automated ways of understanding if our system and subsystems are working as expected. We need automated tests. The character of those tests changes slightly for our AI (sub)systems, but that is something we will unwrap soon.
Hardware in the AI Age
Before we tackle those two themes, let’s have a look again at the hardware part. This is not a change being introduced by AI, but predates it. The availability of cloud technologies, for example provided by AWS, GCP, and Azure, allows us to abstract away from concrete hardware as much as possible. Cloud providers offer fast and seamless access to virtual machines, which allows us to spin up new virtual machines running on newer hardware. Given we are able to deploy—IaC (infrastructure as code)—and run automated tests to ensure that our application works fine on the new hardware, we can relatively easily migrate our software stack to newer hardware. In case of not using virtual machines but serverless managed services, we are so far abstracted from actual hardware that we can’t and don’t need to bother with this at all.
Software in the AI Age
Let’s go back to software. The advent of AI delivers us very powerful means to update and migrate software systems. Current coding AI agents like Amazon’s Kiro or Anthropic’s Claude Code can support developers in migrating to new versions of, for example, libraries. Work which has been cumbersome in the past becomes easier. Given the automated tests, these updates can be done efficiently and more frequently. This is a huge improvement.
Beside coding AI agents, we also now have dedicated services for larger migrations. For example, AWS Transform provides an agentic AI approach to enterprise modernization. This is just an example; there are more and more to come.
So that got way easier. Still, we need tests.
The second theme is a little bit more complicated. What about those AI subsystems we are using now in our software systems? Usually we refer to them as models, while they are something else. I ranted about this in [1] and rest my case for now. So we call them models. Two main ways to integrate models in applications have been broadly adopted. Either we, for example, use open-weight models which we deploy and run by ourselves, or we use models which are hosted as a managed service and are integrated into our applications via some kind of an API. Only a few of us will run their own developed models. The implications of choosing one or the other option are similar to if we decide to run software ourselves or consume it in a kind of a SaaS offering. In the former case, we are able to decide to run model versions as long as we want, but need to maintain them ourselves. In the latter case, we are depending on how long specific versions of models are being provided by our SaaS partner. There are two important differences though: 1) the typical lifetime of a model version and 2) the cost of hosting models on our own.
There are two driving forces in terms of defining the difference. Currently, model evolution is super fast and models in general need a lot of resources to be run.
As a consequence, we see literally every week a new model or a new model version superseding older versions of the same model and quite possibly all other models on the market. For a model consumer, the challenge is to decide if they should as soon as possible change to newer model versions or even change the model provider. This comes with effort which is only manageable if the consumer has ways to automatically evaluate new models, or model versions, and test them on their use case. Even then it takes time and effort and quite possibly distracts from feature development. So consumers try not to hop on every new model but rather reduce the frequency of change, balancing possible performance/cost benefit against effort of change and risk of change.
At the same time, model providers need, like traditional software providers, to reduce the number of different model versions being available for their customers. Like traditional software, each version in production needs its own support and resources. For AI models, the resources become even more crucial. State-of-the-art frontier models require a lot of accelerated compute resources which are scarce. So, model providers are requiring consumers to even faster move to new models to free compute resources for the current model versions.
If we take, for example, the example of Anthropic Claude models [2], we can clearly see that Anthropic aggressively moves older model versions in stages towards retirement. And this is not an exception within the way AI labs treat older model versions. Other providers have similar lifecycles for their models. Also, when you consume models through third-party platforms like Amazon Bedrock, you need to keep an eye on the lifecycle of the models [3].
Evolutionary Architectures to the Rescue?
Yes. Actually, like before. Software is not a wooden chair which you craft once and hopefully use forever. You need to maintain it. You need to be able to evolve it.
Evaluation of new models and testing models sounds easier than it is. Models are inherently non-deterministic. Unless explicitly configured to produce deterministic results, two times the same request will likely produce different answers. A use case potentially including multiple model invocations, possibly taking model output as input for the next model invocation, can quickly propagate small differences to different outcomes.
And this is good. In general. Unless you need deterministic results. In this case, using a model is likely not a good option. Often, it helps to decompose the use case at hand and split it into parts which require deterministic results and parts where you benefit from agency, planning, and reasoning capabilities of models. You should use models for the latter part and deterministic tools for the former part. I wrote about this in [5].
Back in 2024, I spent a lot of time talking to customers about how they could engineer their prompts to create better and, importantly, more reliable results from their model invocations, allowing them to scale use cases for enterprise applications. At the time, I always presented the slide below talking about how test and test-driven prompt engineering enables evolution of their applications and allows them to benefit from new models and model versions.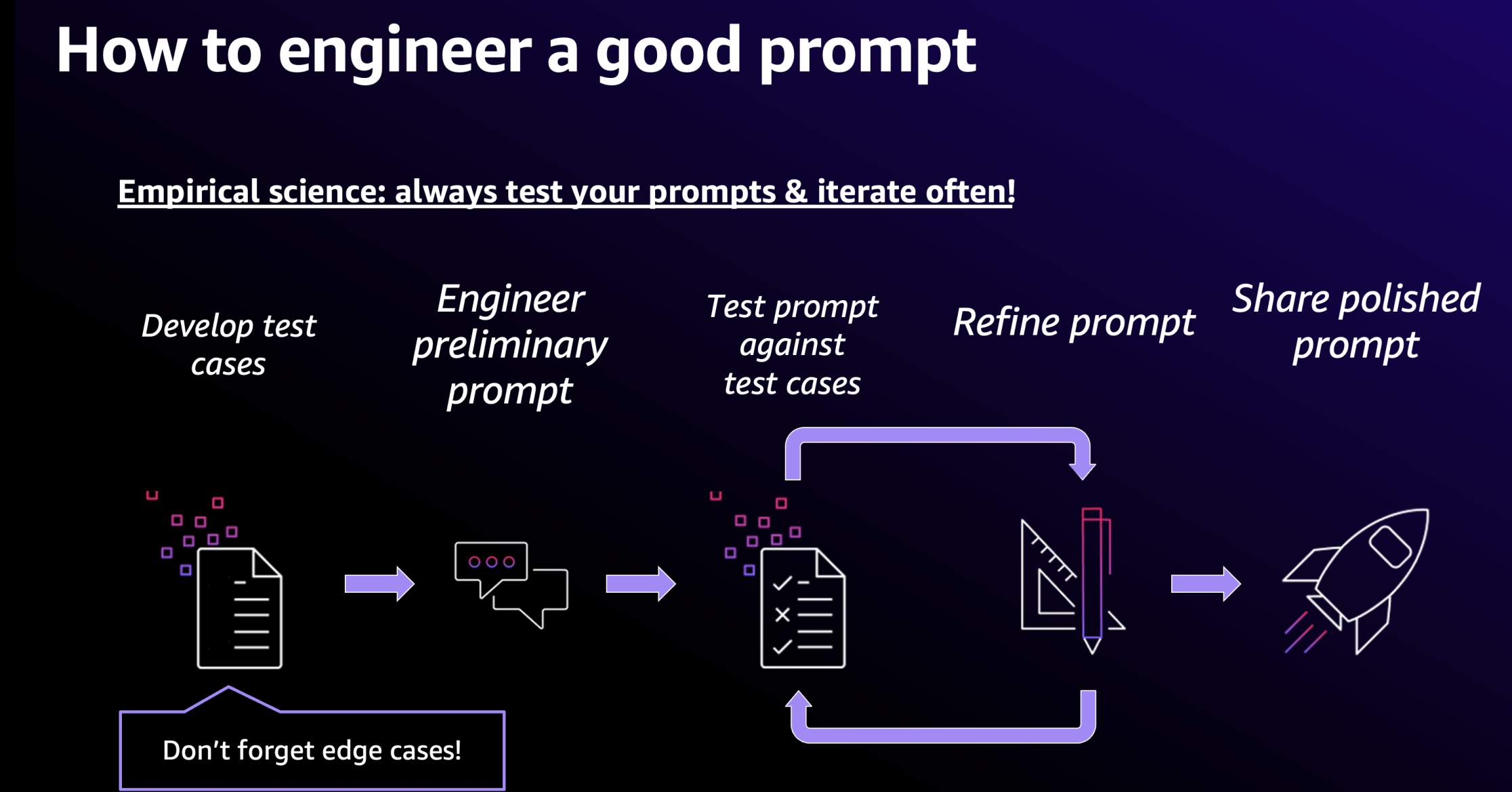
The original diagram originates, by the way, from Anthropic and has been used in the 2023 edition of the AWS re:Invent conference. And it still stays true.
The good thing is that in the meantime, frameworks and services for evaluating and testing kept evolving. For example, both AWS services which allow you to run, customize, and build AI models—Amazon SageMaker and Amazon Bedrock—provide managed service offerings to build your own test harness and evaluate new models.
This is something to pick up in a dedicated article as the current article already got rather lengthy. Let me know if you are interested in a continuation and maybe inspire me—which approach and tools are you using to evaluate and test your models?
Conclusion
Maintenance of IT systems stays a topic. We need to maintain them, and the best way to prepare for this is to build them as evolvable systems. This didn’t change. What changed with the rise of current AI technologies, like LLMs and AI agents, is that both the required speed of evolution and the ability to evolve fast increased. What is open from the article is how to specifically test and evaluate models—something to be picked up in the next article.
Let’s finish off with some good news: An additional consequence of staying up-to-date is not just burning but also saving money. Often, you even save more than you burn, as inference—so model invocations and possibly hosting them—becomes an important cost factor for modern AI systems. Inference becomes cheaper if you are able to evolve your system utilizing the continuous development of smaller and more capable models.
Thanks for staying with me through this rather long read. Please share your thoughts and don’t shy away from reaching out to discuss further.
Sources
[1] Model versus Compound Systems: https://www.linkedin.com/pulse/when-model-isnt-just-redefining-ai-systems-builders-era-christoph-k6v1e/
[2] Claude Model Deprecation: platform.claude.com/docs/en/about-claude/model-deprecations
[3] Amazon Model Lifecycle: docs.aws.amazon.com/bedrock/latest/userguide/model-lifecycle.html
[4] AWS Transform: aws.amazon.com/transform/
[5] Tool Use: https://www.linkedin.com/pulse/from-chaos-control-building-predictable-ai-agents-get-christoph-kzlxe/
Cross-posted to LinkedIn