On the Loop, Not In It — But Code Quality Still Matters
On the Loop, Not In It — But Code Quality Still Matters
Yesterday one of my AI agents wasted 15 minutes chasing a bug that didn’t exist. The function was called transformPayload() — but it didn’t transform anything. It validated. The agent built three layers of transformation logic on top of it before realizing the name was a lie. I’ve seen this pattern dozens of times now. And it’s exactly why I think Kief Morris’s latest piece gets the big picture right but undersells one critical detail.
The Loop Framework
Morris, a global cloud technology specialist at Thoughtworks, just published “Humans and Agents in Software Engineering Loops” [1] as part of the Thoughtworks “Exploring Gen AI” series — and it’s the clearest framing I’ve seen of where humans should sit in the age of agentic coding.
He distinguishes two loops: the “why loop” (turning ideas into outcomes) and the “how loop” (building the software).
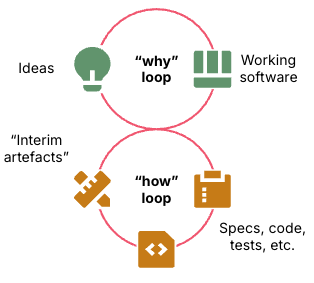
Figure 1: The why loop iterates over ideas and software, the how loop iterates on building the software. Source: Kief Morris [1]
Then he maps three positions for humans:
Outside the loop — vibe coding. You describe what you want, the agent builds it. Fast, fun, fragile. Jeremy Howard’s analogy captures this perfectly: agentic coding is a slot machine — you craft your prompt, pull the lever, and hope for the best [9]. His data shows a tiny uptick in what people actually ship, and almost everybody who got enthusiastic about AI-powered coding changed their mind when they looked back at how much of what they built they’re actually using.
In the loop — reviewing every line. Thorough, but you become the bottleneck. Reports on developer productivity with AI show mixed results, partly because humans spend more time specifying and reviewing than they save.
On the loop — you design the constraints, the agent operates within them. You don’t inspect every output — you improve the system that produces the output. Morris connects this to the emerging practice of “Harness Engineering” [2] — building and maintaining the collection of specifications, quality checks, and workflow guidance that keep agents in check.
I’m largely on board with “on the loop.” It maps directly to how I work with Kiro every day — skills define the workflow, steering files set the constraints, hooks enforce quality gates. The agent operates within that harness. I’m on the loop. I wrote about this pattern in detail in my earlier piece on building predictable AI agents [3], and it’s the foundation of how I scale development with specialized Kiro subagents [4].
This shift also changes what it means to be a developer. Being “on the loop” demands broader skills — architecture, design thinking, constraint definition — not just coding. It’s what I called the “Renaissance Developer” [11]: the developer who thrives in the age of AI isn’t the fastest typist, but the one who can think across disciplines and design the systems that agents execute within.
Where I Push Back: Code Quality Isn’t Optional
Morris raises a provocative question early in the piece:
“It doesn’t matter whether a variable name clearly expresses its purpose as long as an LLM can figure it out. Maybe we don’t even need to care what language the software is written in?”
To his credit, he goes on to argue against this himself: “When LLMs can more quickly understand and modify the code they work faster and spiral less.” But I think this deserves a much stronger defense — because the rhetorical question alone is dangerous if taken at face value.
Variable names aren’t just for compilers — they’re context. They’re the first thing both humans and agents read to build a mental model of the codebase. My transformPayload() story from the opener? That’s not an edge case. Anyone who has spent serious time with AI coding agents has seen this pattern: the agent reads a poorly named function, builds confidently on a wrong assumption, and spirals for iterations before discovering the name was misleading.
I’ve literally seen agents say things like: “I see that doSomeMagic() was expected to handle authentication, but it actually performs data serialization — this is why my approach failed.” Names matter. They’re the cheapest form of documentation, and bad names don’t just slow agents down — they send them confidently in the wrong direction.
And it goes beyond naming. Brittle code is brittle code, regardless of which entity is building and maintaining it. Tight coupling, hidden side effects, implicit dependencies — these aren’t just “developer experience” problems. They’re the exact patterns that cause agents to spiral. When an agent changes one module and three unrelated tests break, it doesn’t understand why any better than a junior developer would. It just burns more tokens trying. I explored this dynamic in my piece on IT system maintenance in the age of AI [10] — systems that aren’t maintained decay, and that decay compounds whether humans or agents are doing the work. Unmaintained code doesn’t just get harder for humans to change — it gets harder for agents too.
I’d go further than Morris: clean code isn’t a nice-to-have in the age of agents — it’s a prerequisite for agent productivity. The cleaner your codebase, the fewer tokens your agents waste, the fewer spirals they enter, and the more reliably they ship.
From Vibe Coding to Spec-Driven Development
So if we’re “on the loop,” what does the loop actually look like? This is where spec-driven development comes in — and where the abstract framework becomes concrete.
Kiro [5] pioneered the concept of spec-driven development as a structured alternative to prompt-and-pray coding. As the Kiro team describes it: rather than treating the LLM as a code generator first, it should be a thinking partner throughout the entire development lifecycle [6]. Instead of jumping straight into code generation, you externalize the planning phase into specification files that serve as persistent context.
The flow works in three phases:
- Requirements — you describe a feature in natural language. Kiro generates structured requirements using the EARS format (Easy Approach to Requirements Syntax): “When the user submits a form with invalid email, the system shall display an inline error message.”
- Design — Kiro produces a technical design: which components to create or modify, what interfaces to define, what data flows to implement. You review and adjust.
- Implementation tasks — the design breaks down into discrete, testable tasks. Each task has explicit acceptance criteria. The agent executes them one by one.
Each phase produces artifacts that constrain the next. The agent doesn’t just generate code — it generates code that satisfies explicit acceptance criteria derived from requirements you approved. And when something breaks, the spec tells you whether the code is wrong or the requirement was incomplete.
This is Morris’s “on the loop” made tangible. The spec is the harness. The human designs it, the agent runs within it.

Not Every Problem Starts with Requirements
What makes this even more practical is that Kiro recently shipped two new spec types [7] that acknowledge a reality Morris also touches on: not every task is a greenfield feature.
Design-first specs let you start with the technical architecture rather than requirements. You’re migrating a monolith to microservices? The architecture is already clear — event-driven, async messaging, specific latency requirements. You don’t need to start from “what should this do?” — you need help implementing what you’ve already designed. Kiro generates the design document first, then derives feasible requirements from it. This is “on the loop” for brownfield work.
Bugfix specs take a surgical approach. Instead of describing what to build, you describe what’s broken, what should happen instead, and — critically — what must stay the same. Kiro generates a structured document with three sections: Current Behavior, Expected Behavior, and Unchanged Behavior. This forces explicit thinking about blast radius, which is exactly the kind of constraint that keeps agents from “fixing” one thing while breaking three others.
Both of these map directly to Morris’s insight that the “on the loop” approach means changing the harness, not the output. Whether you’re building a new feature, implementing an existing design, or fixing a bug — the spec is the harness, and the human stays on the loop by designing it.
Property-Based Testing: The Missing Piece
There’s one more layer that makes this work — and it connects directly to the code quality argument.
Traditional unit tests check specific examples: “given input X, expect output Y.” They’re necessary but insufficient. An agent can make all your example-based tests pass while introducing subtle bugs for inputs nobody thought to test.
Property-based testing flips this. Instead of writing individual test cases, you define properties that must always hold: “this function must never return negative values,” “the output list must always be sorted,” “serializing then deserializing must return the original object.” The testing framework then generates hundreds of random inputs to verify those properties.
Kiro generates property-based tests as part of every spec workflow [7]. For bugfix specs, this is particularly powerful: Kiro creates tests that verify the bug exists in the current implementation, tests that verify the fix resolves it, and tests that verify unchanged behavior continues working. Without these, it’s difficult to check whether the agent actually fixed the bug for a comprehensive set of conditions — and that the changes were indeed surgical.
This is the perfect complement to spec-driven development. The spec defines what should be true. Property-based tests verify it holds under conditions no human — and no agent — would think to check. It’s a safety net that catches the class of bugs that slip through when agents confidently produce code that passes all the obvious tests but fails on edge cases.
Combined with clean code and clear naming, you get a system where agents can operate with high autonomy and high reliability. The constraints aren’t just rules — they’re a self-reinforcing quality loop.
The Agentic Flywheel
Morris takes this one step further with what he calls the “agentic flywheel” — agents that don’t just operate within the harness but help improve it.
Figure 2: Human directs agent to build and improve the how loop. Source: Kief Morris [1]
Feed them pipeline metrics, production data, user journey logs, and they can recommend improvements to the constraints themselves. As Morris puts it, at some point this might look like humans out of the loop again — but by engineering the harness first, you get robust, maybe even anti-fragile systems that continuously improve themselves.
This isn’t theoretical. In my Kiro setup, I run a retrospective skill at the end of each session. It analyzes what went well and what didn’t, then proposes improvements to the skills and steering files — the very constraints the agent operates within. The harness evolves. The agent gets better. The loop tightens. I described this self-improving pattern in my article on building predictable agents [3] — and it’s been running in production for months now.
That’s the real promise of “on the loop”: not a static set of rules, but a living system that learns from its own execution.
The Takeaway
Morris is right that the future is “on the loop.” Birgitta Böckeler’s companion piece on Harness Engineering [2] adds the practical dimension of what that harness looks like. And the broader Thoughtworks “Future of Software Development” retreat [8] where these ideas were workshopped shows this isn’t one person’s opinion — it’s an emerging consensus among practitioners.
But being on the loop doesn’t mean we stop caring about what’s inside it. Clean code, clear naming, explicit contracts, spec-driven workflows, and property-based tests aren’t relics of the human-only era — they’re the foundation that makes agentic coding actually work.
The agents are only as good as the constraints we give them. Design those constraints well — and then let the agents help you make them better.
What’s your experience — do your agents produce better code when the existing codebase is clean?
Sources:
[1] Kief Morris — “Humans and Agents in Software Engineering Loops” (Thoughtworks, Exploring Gen AI series): https://martinfowler.com/articles/exploring-gen-ai/humans-and-agents.html
[2] Birgitta Böckeler — “Harness Engineering” (Thoughtworks, Exploring Gen AI series): https://martinfowler.com/articles/exploring-gen-ai/harness-engineering.html
[3] Stefan Christoph — “From Chaos to Control: Building Predictable AI Agents That Get Smarter Over Time”: https://schristoph.online/blog/from-chaos-to-control-building-predictable-ai-agents-that-ge/
[4] Stefan Christoph — “Kiro Subagents: Scaling Development with Specialized AI Agents”: https://schristoph.online/blog/kiro-subagents-scaling-development-with-specialized-ai-agent/
[5] Kiro — Spec-Driven Agentic IDE: https://kiro.dev
[6] Kiro Blog — “From chat to specs: a deep dive into AI-assisted development with Kiro”: https://kiro.dev/blog/from-chat-to-specs-deep-dive/
[7] Kiro Blog — “New spec types: fix bugs and build on top of existing apps”: https://kiro.dev/blog/specs-bugfix-and-design-first/
[8] Martin Fowler — “The Future of Software Development Retreat”: https://martinfowler.com/bliki/FutureOfSoftwareDevelopment.html
[9] Stefan Christoph — “Agentic Coding is a Slot Machine — and We Need Better Guardrails”: https://schristoph.online/blog/agentic-coding-slot-machine/
[10] Stefan Christoph — “IT System Maintenance in the Age of AI”: https://schristoph.online/blog/it-system-maintenance-in-the-age-of-ai/
[11] Stefan Christoph — “The Dawn of the Renaissance Developer”: https://schristoph.online/blog/the-dawn-of-the-renaissance-developer/
#AgenticCoding #SoftwareEngineering #CodeQuality #AI #Kiro #SpecDrivenDevelopment