When Thinking Twice Helps — And When It Doesn't
The Saturday Morning Experiment
Last Saturday, I installed a Python library, pointed it at Amazon Bedrock, and asked a model the same questions three times — with zero, one, and three rounds of self-reflection.
The results surprised me.
Q Refl Time Acc Comp Nuan Total
1 0 3.0s 4 3 3 10
1 1 5.5s 4 2 3 9
1 3 8.8s 4 3 4 11
2 0 2.6s 4 2 2 8
2 1 5.7s 4 2 2 8
2 3 8.5s 4 2 2 8
3 0 3.1s 1 1 1 3
3 1 5.2s 1 1 1 3
3 3 8.6s 1 1 1 3
Q is the question number, Refl the number of self-reflection rounds (0 = straight answer, 1 = one revision, 3 = three revisions). Acc, Comp, and Nuan are the judge’s scores for Accuracy, Completeness, and Nuance — each on a 1-5 scale, 15 max total.
Three questions. Three reflection depths. One clear pattern: self-reflection helps when the model already knows the topic — and does nothing when it doesn’t.
Three questions isn’t a statistically significant sample — this isn’t a research paper. But each question was deliberately chosen to represent a different level of model familiarity: well-known, domain-specific, and bleeding-edge. The pattern they reveal aligns precisely with the paper’s findings across 5,000 problems. The paper provides the rigor; this experiment provides the practitioner’s lens.
What Is Self-Reflection?

Self-reflection: the model critiques and revises its own response.
The idea is simple: instead of accepting the model’s first answer, you ask it to review and revise its own response. Think of it as a built-in peer review — the model critiques itself and tries again.
A research paper by Jack Butler and Nikita Kozodoi [1] systematically tested this across 10 LLMs on Amazon Bedrock. Their accompanying blog post [5] provides a practical walkthrough of the approach. The findings are striking:
- Mathematical reasoning: Up to 220% accuracy improvement. Amazon Nova Micro jumped from 22% to 71% with just one reflection round.
- Sentiment analysis: Consistent but modest gains across most models.
- Translation: Mixed results — Claude improved, Nova performed better without reflection.
- Text-to-SQL: Self-reflection often hurt performance.
The pattern? Self-reflection amplifies existing capability. It doesn’t create new knowledge.
You might think that’s obvious — but after OpenAI’s o1 and o3 showed dramatic improvements from “thinking longer,” many teams assumed more inference-time compute is a universal quality lever. It isn’t. The distinction between reasoning amplification and knowledge injection is critical for architecture decisions, and easy to get wrong.
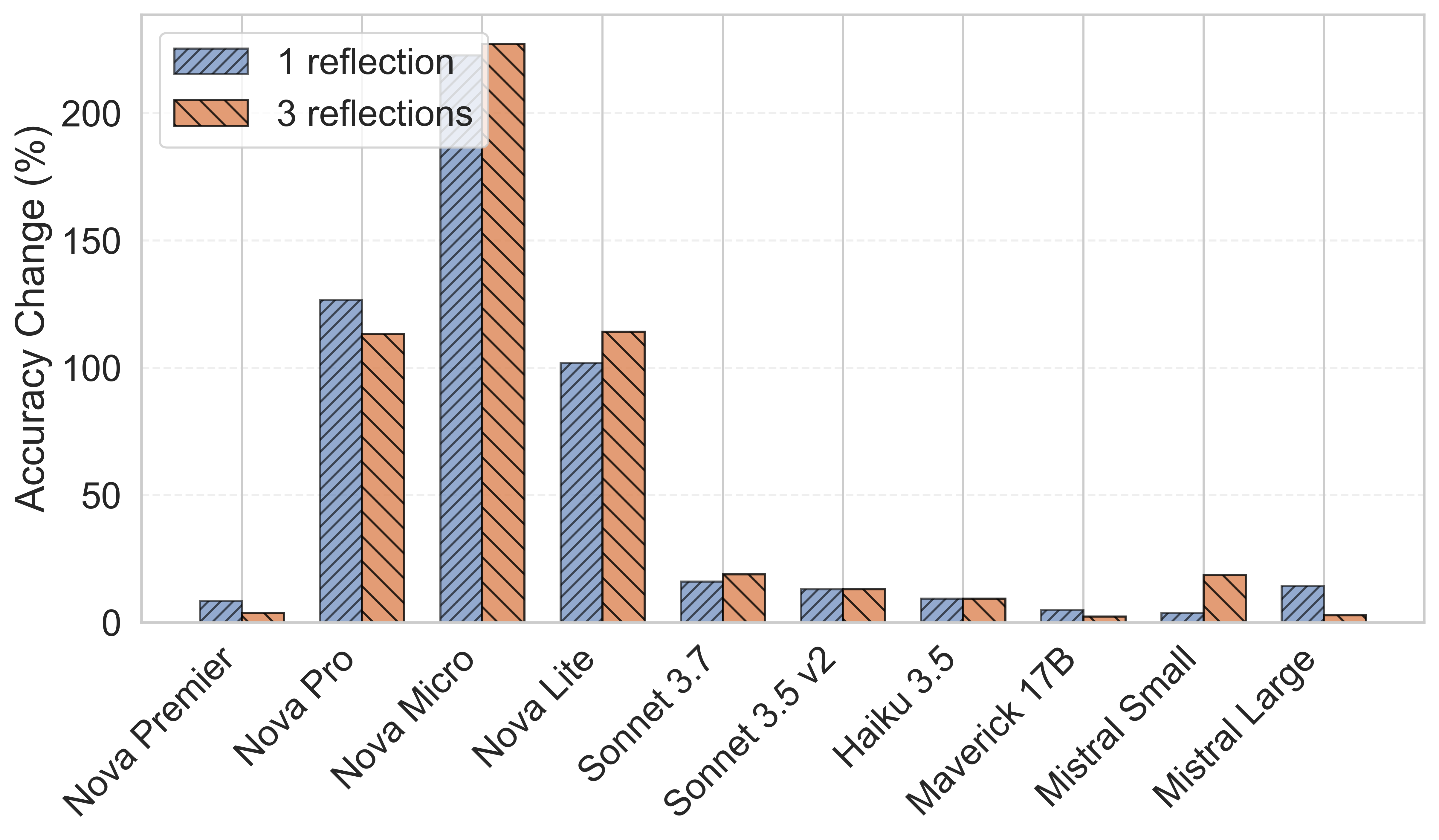
Relative accuracy gains from self-reflection across 10 LLMs on Math500. Smaller models like Nova Micro benefit dramatically (220%), while larger models show modest but consistent improvements. Source: Butler et al. [1]
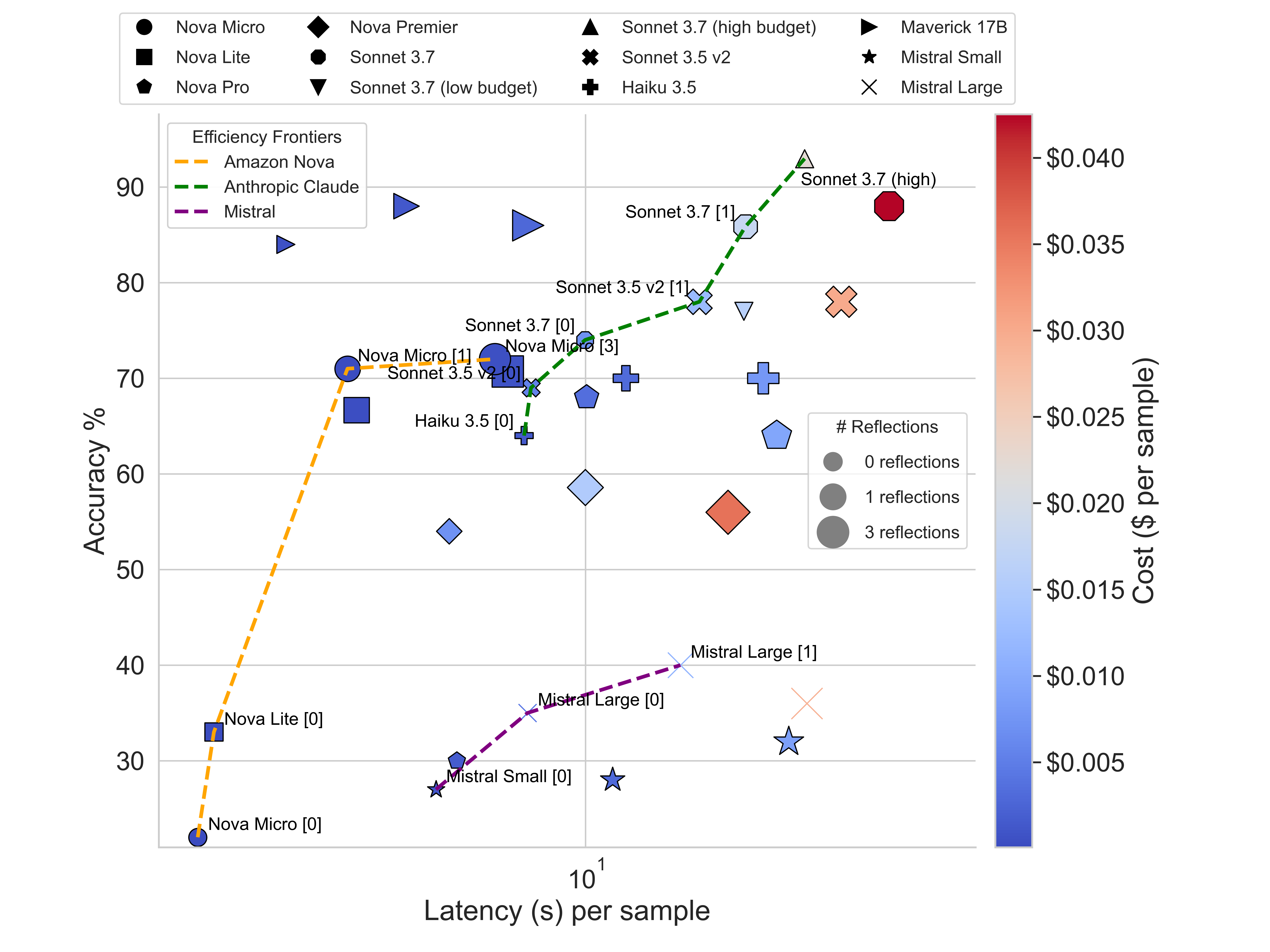
Pareto frontier: accuracy vs latency with cost as color gradient. Nova Micro with 1 reflection reaches the same accuracy as Sonnet 3.5 v2 at a fraction of the cost. Source: Butler et al. [1]
My Experiment: Real Questions, Real Ground Truth

Three questions, three levels of model familiarity — from well-known to bleeding-edge.
I didn’t want to test on math puzzles. I wanted to test on the kind of questions I actually deal with as a Solutions Architect — nuanced, multi-faceted, requiring both knowledge and judgment.
I picked three questions from my own research notes where I already had well-researched answers. These are topics I’ve been actively exploring as a Solutions Architect — each representing a different level of model familiarity:
- “Is RAG still needed with 1M+ token context windows?” — I’ve been following the RAG vs long context debate closely. With context windows growing rapidly, customers keep asking whether retrieval architectures are still worth the complexity. This is a well-established topic with plenty of training data coverage.
- “How should enterprises handle LLM deprecation?” — This came from a recent deep dive into model lifecycle management. AI model deprecation cycles are compressed to 12-18 months vs 5-10 years for traditional software — a new class of infrastructure risk. The answer requires Bedrock-specific knowledge (lifecycle states, migration guarantees) that’s less likely to be in training data.
- “What are MCP Sampling and Elicitation in AgentCore?” — The Model Context Protocol has evolved into stateful collaboration patterns, and AWS just launched support for these in AgentCore Runtime in March 2026. This is bleeding-edge — released weeks before my test.
I used the open-source bHive library [2] — a Bedrock wrapper that makes self-reflection a one-liner:
from bhive import Hive, HiveConfig
client = Hive()
config = HiveConfig(
bedrock_model_ids=["eu.amazon.nova-micro-v1:0"],
num_reflections=1,
)
response = client.converse(messages, config)
For the test model, I chose Amazon Nova Micro — the smallest and cheapest model in the Nova family. That’s a deliberate choice. The paper’s most interesting finding is that smaller models benefit disproportionately from self-reflection: Nova Micro jumped from 22% to 71% accuracy on math with just one reflection round. If self-reflection can turn a lightweight model into a competitive one, that’s a much more compelling cost story than squeezing marginal gains from an already-expensive frontier model.
For the judge, I used Claude Sonnet 4 — a significantly more capable model. This separation matters: you want the judge to be strictly stronger than the model being tested, otherwise it can’t reliably spot errors or missing nuance. Using the same model as both test subject and judge would be like grading your own exam.
When selecting models for this kind of experiment, consider:
- Test model: Pick the model you’d actually deploy in production. If cost matters (and it usually does), start with a smaller model and see how far reflection takes it.
- Judge model: Pick the strongest model you have access to. The judge runs once per evaluation, not per user request, so cost is less of a concern.
- Region: I used EU inference profiles (
eu.amazon.nova-micro-v1:0,eu.anthropic.claude-sonnet-4-20250514-v1:0) since my Bedrock access is ineu-central-1. Bedrock now requires cross-region inference profiles for on-demand access — a detail that cost me a few minutes of debugging.
Then I used Claude Sonnet 4 as an automated judge, scoring each answer against my ground truth on accuracy, completeness, and nuance (1-5 each, 15 max).
But what’s “ground truth” here? In machine learning, ground truth is the known correct answer you compare predictions against. For math, it’s obvious — 2+2=4. For open-ended questions, it’s harder. You need a reference answer that’s been verified by a human expert.
This is where my research notes became valuable. As a Solutions Architect, I regularly research customer questions in depth — reading official documentation, checking Slack threads, verifying with service teams, and synthesizing the findings into structured notes. These notes aren’t quick ChatGPT answers — they’re curated, source-backed summaries that I’d confidently share with a customer.
That made them ideal ground truth: human-verified, multi-source, and detailed enough to judge against. For example, my ground truth for the RAG question included specific research benchmarks (LaRA, NIAH), concrete scenarios where RAG wins vs long context, and the hybrid architecture pattern — all backed by sources. The model lifecycle ground truth included Bedrock-specific details like the Active → Legacy → EOL states and the 12-month minimum guarantee.
Finding good ground truth is the hardest part of any LLM evaluation. If you don’t have curated reference answers, you’re essentially asking one model to judge another with no anchor — which is why so many “vibe-based” evaluations produce misleading results.
The Results Tell a Story
Question 1 — RAG vs Long Context (well-known topic): Self-reflection worked. The 3-reflection answer scored 11/15 vs 10/15 at zero reflections. The model already understood RAG well — reflection helped it surface tradeoffs and caveats it initially glossed over.
Question 2 — Model Lifecycle Management (domain-specific): Self-reflection did nothing. Score stayed at 8/15 across all reflection depths. The model knew general IT lifecycle practices but lacked Bedrock-specific knowledge (the 12-month guarantee, the Active → Legacy → EOL states). No amount of reflection could surface facts it never learned.
Question 3 — MCP Sampling & Elicitation (very recent feature): Self-reflection couldn’t help. Score: 3/15 across the board. Nova Micro didn’t know what MCP stands for in this context — it hallucinated “Model Confidence Prediction” instead of Model Context Protocol. Three rounds of reflection just produced three rounds of increasingly confident wrong answers.
This is worse than just “not helping.” It’s hallucination amplification: when the model’s initial answer is wrong due to missing knowledge, reflection asks it to “review and improve” — which it interprets as “make this more detailed and convincing.” Without an external signal that it’s wrong, the model optimizes for coherence within its incorrect frame. More thinking made it more confidently wrong.
What This Means in Practice
The research paper’s conclusion holds up in my hands-on test: self-reflection is a reasoning amplifier, not a knowledge injector.
This has direct implications for how we build AI systems:
Where self-reflection shines:
- Mathematical and logical reasoning
- Code review and debugging (the model catches its own mistakes)
- Nuanced analysis where the model has strong training data coverage
- Content quality improvement (the Zalando case study in the paper showed an 88% reduction in localization issues for French content [1])
Where it falls short:
The Sankey diagrams from the paper make this vivid. Nova Micro (top) jumps from 30% to 64% correct in a single reflection — a massive self-correction. But then it plateaus. Claude Sonnet 3.5 (bottom) starts at 68% and improves gradually to 74% across multiple rounds. Different models, different reflection dynamics.
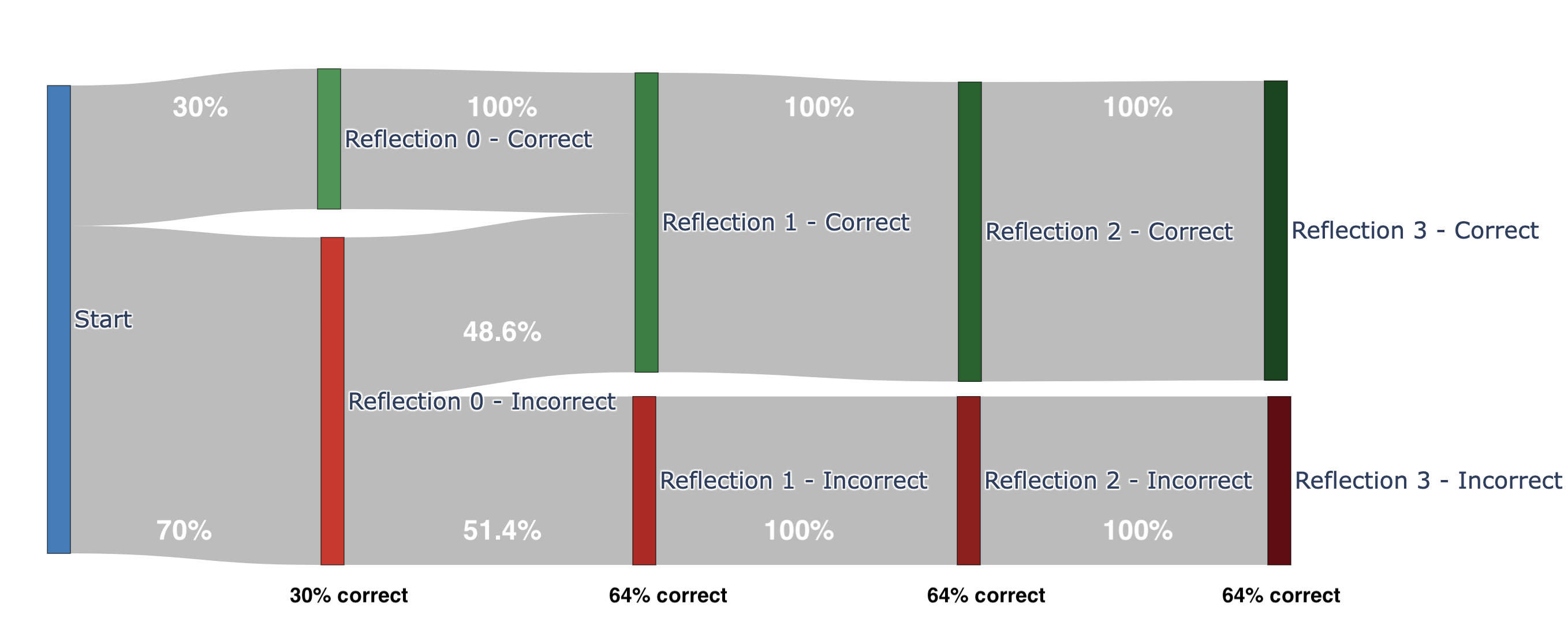
Nova Micro: dramatic first-round correction (30% → 64%), then plateau. Source: Butler et al. [1]
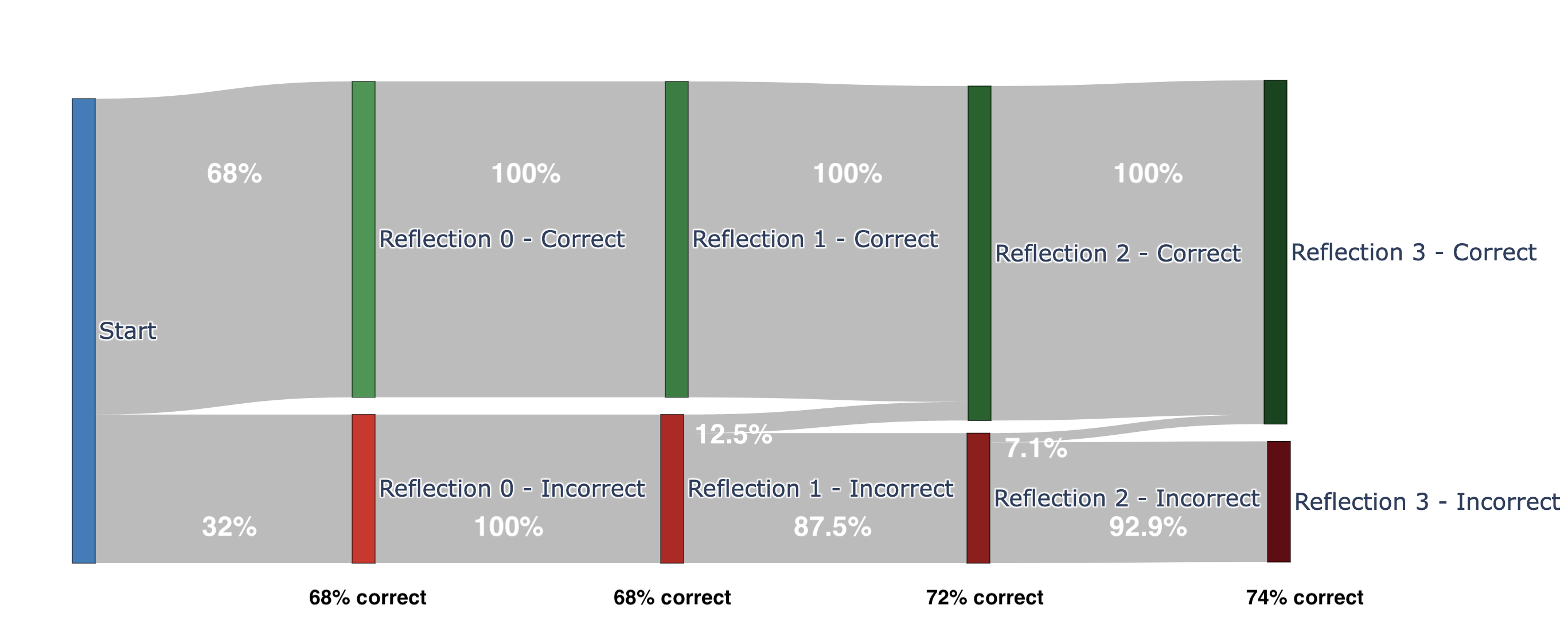
Claude Sonnet 3.5: steady incremental improvement (68% → 74%) across rounds. Source: Butler et al. [1]
- Domain-specific knowledge the model wasn’t trained on
- Very recent information (post-training cutoff)
- Tasks where the first answer is already near-optimal
A note on built-in thinking modes: Models like Claude (extended thinking) and Nova (reasoning mode) have native “thinking” capabilities that serve a similar purpose. The key difference: built-in thinking is optimized by the model provider and typically faster per quality unit. External reflection via bHive is model-agnostic and — critically — lets you inject external verification between rounds. The two approaches are complementary, not competing. Use built-in thinking when available; add external reflection when you need custom verification logic.
The real unlock: Combining self-reflection with external knowledge. The bHive library supports a verifier function — a callback between reflection rounds that can inject external context. Imagine a RAG retrieval step between reflections: the model answers, retrieves relevant documents, then reflects with new evidence. That’s where the architecture gets interesting.
I haven’t tested this combination yet — that’s the next experiment. But the hypothesis is clear: take the MCP question that scored 3/15, add a RAG step that retrieves the actual AgentCore documentation between reflection rounds, and see if the score jumps. The bottleneck was missing knowledge, not reasoning quality — so injecting knowledge mid-reflection should close the gap.

The verifier pattern: inject external knowledge between reflection rounds.
The Bigger Picture

Self-reflection amplifies reasoning. It doesn’t fill empty shelves.
This connects to a pattern I keep seeing: the most effective AI architectures separate what the model is good at from what it isn’t.
LLMs are reasoning engines, not databases. Self-reflection makes them better reasoners. But for knowledge — especially current, domain-specific knowledge — you need retrieval, tools, and structured data. The model should think; the infrastructure should know.
This is exactly why patterns like RAG [3], tool use in Bedrock Agents, and MCP-based architectures matter. They let the model focus on what it does best while offloading what it doesn’t.
Try It Yourself
The bHive library is open source and takes five minutes to set up:
pip install "git+https://github.com/aws-samples/sample-genai-reflection-for-bedrock.git"
Start with a simple comparison — ask the same question with 0 and 1 reflections and see if the quality improves. Then try the verifier pattern with your own domain knowledge. The results might surprise you.
One tip: don’t just test on general knowledge questions where the model already shines. Test on your domain — the niche, proprietary, or recent topics where you know the right answer and the model might not. That’s where you’ll learn whether reflection is the right tool, or whether you need retrieval first.
💬 Have you experimented with inference-time optimization techniques? What worked — and what didn’t?
Sources:
[1] Butler, J. & Kozodoi, N. — “Trading Quality, Cost, and Speed During Inference-Time LLM Reflection” (2025). Paper: arxiv.org/html/2510.20653v1 | Code: github.com/aws-samples/sample-genai-reflection-for-bedrock
[2] bHive — Open-source Bedrock wrapper for inference-time LLM techniques. github.com/aws-samples/sample-genai-reflection-for-bedrock
[3] My earlier post on RAG architectures: schristoph.online/blog/most-comprehensive-overview-on-rag-i-have-seen-we-came-a-lon/
[4] My deep dive on model lifecycle management: schristoph.online/blog/model-lifecycle-management/
[5] Butler, J., Kozodoi, N., Afolabi, Z. (AWS Generative AI Innovation Center) — “Boost Your LLM Performance on Amazon Bedrock with Self-Reflection”: builder.aws.com